Setting up web scraping python environment on Google Compute Engine
Disclaimer: Nothing unique is described here. Post is made with intent to have a checklist of my setup. It’d be great if it might be interested or helpful to someone else
One of my project requires a daily web scraping and storing data on database. Project includes the following components:
- Python 3.7
- Postgres
- Cron
Past years this project was running on AWS EC2 t2.micro instance and this was enough. I was going to switch from AWS to GCP in order to test and evaluate new service.
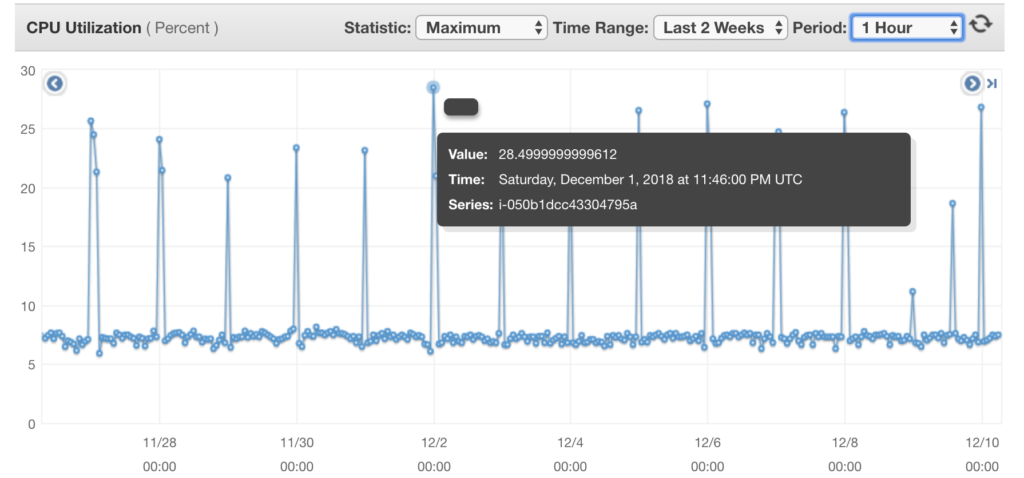 Max. of CPU utilization on AWS EC2 micro
Max. of CPU utilization on AWS EC2 micro
It’s super easy to fill in several forms and get your account.
I choose g1-small machine with 1 vCPU and 1.7 GB memory which should be enough for my experiments. During machine configuration process you can add your ssh key.
After setup you can login with SSH directly from browser or by your preferable client with ssh key provided in the previous step
ssh -i "~/.ssh/id_rsa" pavel@2.248.5.16
where pavel is name which I give to my ssh key and 2.248.5.16 is public IP address of my instance.
After login to the newly created instance I have to setup all required tools
Debian machine comes with Python 3.5 installed. My projects use python 3.7, so I need to install this Python version.
Install build-essential
sudo apt-get install build-essential
Build Python from sources
wget https://www.python.org/ftp/python/3.7.1/Python-3.7.1.tgz
tar xvf Python-3.7.1.tgz
cd Python-3.7.1
./configure --enable-optimizations
make -j8
sudo make altinstall
python3.7
It took about 40 minutes on this machine

Official postgres site provides great instruction on how to install postgres version which you need. create file
sudo vi /etc/apt/sources.list.d/pgdg.list
with the following content
deb http://apt.postgresql.org/pub/repos/apt/ stretch-pgdg main
Then run
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | sudo apt-key add -
sudo apt-get update
apt-get install postgresql-11
After success Postgres installation we need to perform initial configuration. Setup postgres user password by the following command.
sudo -u postgres psql -c "ALTER USER postgres PASSWORD 'your_password';"
sudo vim /etc/postgresql/11/main/pg_hba.conf
change config file with the following values
# Database administrative login by Unix domain socket
local all postgres md5
# "local" is for Unix domain socket connections only
local all all md5
Restart Postgres
sudo /etc/init.d/postgresql restart
Create new user for using in your development environment
createuser -U postgres -d -e -E -l -P -r -s <my_name>
run crontab -e and add the following lines to its config
SHELL=/bin/bash
PYTHONIOENCODING=utf8
0 0 15 * * python /home/pavel/projects/p1/src/scraper1.py all
0 * * * * python /home/pavel/projects/p1/src/scraper1.py latest
0 * * * * python /home/pavel/projects/p1/src/s1/scraper2.py
Google Cloud Compute vm had no swap file. So we need to create one
sudo dd if=/dev/zero of=/var/swap bs=2048 count=524288
sudo chmod 600 /var/swap
sudo mkswap /var/swap
sudo swapon /var/swap
And then the following line to /etc/fstab to make it permanent.
/var/swap none swap sw 0 0
That’s a complete setup of my web scraping environment. Here’s monitoring of web scraping activity
